Appearance
03 — 训练技巧(Training Techniques)
构建一个神经网络架构只是第一步。真正决定模型能否收敛、收敛多快、泛化多好的,是训练技巧。权重初始化决定了起点;优化器决定了行进路径;学习率调度决定了步长策略;归一化(normalization /ˌnɔːrmələˈzeɪʃən/)层稳定了中间特征分布;正则化(regularization /ˌreɡjələraɪˈzeɪʃən/)手段防止了过拟合(overfitting /ˈoʊvərˈfɪtɪŋ/)。
时间线:
- 2010: Glorot & Bengio 提出 Xavier 初始化
- 2013: Kingma & Ba 提出 Adam 优化器(2015 ICLR)
- 2014: Srivastava et al. 提出 Dropout
- 2015: Ioffe & Szegedy 提出 Batch Normalization 本章将这五个主题串联成一条完整的"训练流水线",每个部分都附有数学公式、直观理解和可运行的 PyTorch 代码。
章节路线:权重初始化 → 优化器进化史 → 学习率调度 → 归一化 → 正则化
1. 权重初始化(Weight Initialization)
1.1 为什么初始化至关重要?
神经网络的训练本质是在损失曲面上进行优化。如果初始权重设置不当:
- 初始化太大 → 激活值爆炸 → 梯度(gradient /ˈɡreɪdiənt/)爆炸 → NaN
- 初始化太小 → 激活值消失 → 梯度消失 → 参数(parameter /pəˈræmɪtər/)不更新
- 初始化全零 → 所有神经元做同样计算 → 对称性无法打破
核(kernel /ˈkɜːrnl/)心原则:保持前向传播和反向传播(backpropagation /ˌbækprəpəˈɡeɪʃən/)中激活值与梯度的方差稳定。
1.2 Xavier(Glorot)初始化
提出于 2010 年,假设激活函数在 0 附近近似线性(如 tanh、sigmoid(/ˈsɪɡmɔɪd/))。
核心思想:每层输出的方差应等于输入的方差。
对于全连接层
要保持
通常使用均匀分布
python
# PyTorch 实现
nn.init.xavier_uniform_(w)1.3 Kaiming(He)初始化
提出于 2015 年,专门针对 ReLU 激活函数。ReLU 将一半的神经元置零,相当于输出方差减半。
要保持方差稳定:
python
# PyTorch 实现(推荐:mode="fan_in", nonlinearity="relu")
nn.init.kaiming_uniform_(w, mode="fan_in", nonlinearity="relu")1.4 LLaMA 的初始化策略
Meta 的 LLaMA 系列采用了更精细的初始化方案:
- 基础标准差设为
0.02 - 对残差层(每个 Transformer(/trænsˈfɔːrmər/) block 中的 attention(/əˈtenʃən/) 和 FFN 输出投影),按层数缩放:
- 这么做是因为残差连接是加性的,深层残差路径会累积方差
python
# LLaMA 风格
def init_llama(weight, num_layers):
nn.init.normal_(weight, mean=0.0, std=0.02 / math.sqrt(2 * num_layers))1.5 对比总结
| 初始化方法 | 适用激活函数 | 方差公式 | 核心思想 |
|---|---|---|---|
| Xavier | tanh, sigmoid | 前向/反向方差一致 | |
| Kaiming | ReLU, LeakyReLU | 考虑 ReLU 置零一半神经元 | |
| LLaMA init | 残差网络(Transformer) | 残差路径方差累积控制 |
2. 优化器进化史(Optimizer Evolution)
2.1 SGD(随机梯度下降)
最简单的优化器,每次用一个小批量计算梯度并更新参数:
其中
直觉:就像盲人下山,每步都沿着最陡方向走。但 SGD 有两个问题:
- 震荡:在峡谷区域(一个方向陡峭、另一个方向平缓),SGD 会在陡峭方向来回振荡
- 鞍点停滞:在高维空间中,鞍点(某些方向梯度为 0)远比局部极小点多,SGD 容易卡住
2.2 Momentum(动量)
模拟物理惯性:不仅看当前梯度,还累积历史梯度方向。
其中
直觉:像一个下坡的球——在平坦区域加速,在振荡区域抵消反向分量。Momentum(/məˈmentəm/) 能显著加速收敛并抑制震荡。
🔍 完整演算:Momentum 动量更新 — 三步迭代手算
📐 公式
动量优化器积累历史梯度来平滑更新方向:
其中
📖 参数含义
| 符号 | 名称 | 含义 |
|---|---|---|
| 参数 | 第 | |
| 梯度 | 损失函数对 | |
| 速度 | 历史梯度的指数滑动平均 | |
| 动量系数 | 控制历史衰减速度,通常取 0.9 | |
| 学习率 | 更新步长 |
📝 公式来源
动量来源于物理中的惯性概念。标准 SGD 只使用当前梯度:
但这样在峡谷地形中会震荡。动量引入速度累积
如果当前梯度与历史速度方向相反(震荡),速度会被抵消;如果方向一致,速度会叠加(加速)。初始速度
当
✏️ 手算演示
设初始权重
Step 1:
Step 2:
对比纯 SGD(
Momentum 在第 2 步只略微下降(
Step 3:
第 3 步方向一致,Momentum 加速下降(
三步对比:
| 步数 | SGD | Momentum | 说明 |
|---|---|---|---|
| 1.000 | 1.000 | 初始状态相同 | |
| 0.920 | 0.920 | 梯度 +0.8,方向一致,结果相同 | |
| 0.980 | 0.908 | 梯度 -0.6,SGD 反弹,Momentum 平滑 | |
| 0.940 | 0.857 | 梯度 +0.4,SGD 慢降,Momentum 加速 |
Momentum 三步净下降
🌍 实际意义
- Momentum 在框架中仅需多维护一个速度向量
,计算开销极小 - 配合 SGD 使用可在 CV 任务上接近 Adam 的效果,且泛化性更好
- PyTorch:
optim.SGD(model.parameters(), lr=0.01, momentum=0.9) 越大历史惯性越强(常见 0.9 或 0.99); 退化为标准 SGD
2.3 AdaGrad / RMSProp
AdaGrad 为每个参数自适应学习率:频繁更新的参数降低步长,稀疏更新的参数增大步长。
问题:
RMSProp 用指数滑动平均代替累加:
2.4 Adam(Adaptive Moment Estimation)
Adam 结合了 Momentum 的一阶矩和 RMSProp 的二阶矩,且有偏差修正防止初期估计偏小。
| 变量 | 含义 | 更新公式 |
|---|---|---|
| 梯度的一阶矩(均值) | ||
| 梯度的二阶矩(未中心化方差) | ||
| 偏差修正后的一阶矩 | ||
| 偏差修正后的二阶矩 |
最终更新:
默认值:
直觉:每个参数有自己的自适应学习率(通过
🔍 完整演算:Adam 优化器 — 三步迭代手算
📐 公式
Adam 维护两个状态:一阶矩
📖 参数含义
| 符号 | 名称 | 含义 |
|---|---|---|
| 梯度 | 第 | |
| 一阶矩 | 梯度的指数滑动平均(均值) | |
| 二阶矩 | 梯度平方的指数滑动平均(未中心化方差) | |
| 一阶矩衰减率 | 控制动量衰减,默认 | |
| 二阶矩衰减率 | 控制自适应率衰减,默认 | |
| 修正一阶矩 | 偏差修正后的动量估计 | |
| 修正二阶矩 | 偏差修正后的方差估计 | |
| 学习率 | 默认 | |
| 小常数 | 防止除零,默认 |
📝 公式来源
Adam = Momentum(一阶矩)+ RMSProp(二阶矩)+ 偏差修正。
初始化时
真实期望应是
恢复无偏估计。
✏️ 手算演示
设初始权重
Step 1:
偏差修正:
更新:
Step 2:
偏差修正:
更新:
Step 3:
偏差修正:
更新:
三步对比:
| 步数 | 有效步长( | ||||||
|---|---|---|---|---|---|---|---|
| +0.5 | 0.05 | 0.00025 | 0.5 | 0.5 | 0.2 | 1.000 | |
| 0.015 | 0.00034 | 0.079 | 0.412 | 0.243 | 0.900 | ||
| +0.2 | 0.034 | 0.00038 | 0.124 | 0.356 | 0.281 | 0.881 | |
| — | — | — | — | — | — | 0.846 |
关键观察:
- 偏差修正:Step 1 中
远小于真实梯度 ,修正后 恢复无偏估计 - 自适应学习率:有效步长
从 0.2 逐渐增加到 0.281——梯度平方和小的方向获得更大步长 - 动量平滑:尽管
方向反转, 仍为正,所以 继续下降而非反弹
🌍 实际意义
- PyTorch:
optim.Adam(model.parameters()),默认参数通常直接可用 - 对学习率较 SGD 不敏感(默认
适用大多数场景) - 适合 Transformer、GAN 等复杂架构,收敛稳定
- 缺点:自适应学习率可能导致泛化性不如精心调参的 SGD+Momentum
- AdamW 通过解耦 weight decay 修复了 Adam 的一个核心缺陷
2.5 AdamW(Decoupled Weight Decay)
Adam 的问题:在实现中通常将
但 Adam 会用
AdamW 将 weight decay 解耦到参数更新之后:
| 优化器 | 参数量 | 自适应 LR | 动量 | Weight Decay |
|---|---|---|---|---|
| SGD | 0 | ✗ | ✗ | 隐含在梯度中 |
| Momentum | +1 (v) | ✗ | ✓ | 隐含在梯度中 |
| Adam | +2 (m, v) | ✓ | ✓ | 耦合在梯度中 |
| AdamW | +2 (m, v) | ✓ | ✓ | 解耦,效果更好 |
3. 学习率调度(Learning Rate Schedules)
3.1 为什么需要调度?
- 学习率太大:损失震荡不收敛
- 学习率太小:收敛极慢,容易陷入局部最优
- 理想策略:初期大步探索 → 后期小步精调
3.2 预热(Warmup)
在训练初期,模型权重尚未稳定,较大的学习率可能导致梯度爆炸。预热阶段线性增加学习率:
为什么预热有效? 初始阶段模型的统计量(Batch Norm 的均值和方差、Adam 的动量估计)还不准确,大步更新可能破坏初始特征。预热给了这些统计量一个"稳定期"。
3.3 余弦退火(Cosine Annealing)
余弦退火将学习率从最大值平滑下降到最小值:
:当前 epoch :总 epoch 数 :初始学习率 :最小学习率(通常为 0)
余弦退火的优势是平滑衰减——相比 Step Decay 的阶梯式下降,余弦退火在每个阶段都不会有突变,更适合细粒度收敛。
3.4 线性衰减
实现简单,但与余弦退火相比,在后期下降过快,可能没有足够时间"精调"。
3.5 常见调度
| 调度 | 公式 | 特点 | 适用场景 |
|---|---|---|---|
| Constant | 简单但次优 | 小规模任务 | |
| Step Decay | 每 | 阶梯下降 | 传统 CV 任务 |
| Warmup + Cosine | 线性上升 + 余弦下降 | 平滑,效果好 | 主流推荐(LLM 预训练标配) |
| Linear | 线性下降 | 简单 | 微调 |
4. 归一化(Normalization)
4.1 Batch Normalization(批量归一化)
对每个 mini-batch 计算均值和方差,对激活值做归一化,再用可学习参数
优点:
- 允许使用更大的学习率
- 对初始化不敏感
- 有一定正则化效果(因为 batch 均值有噪声)
缺点:
- 依赖 batch size(batch 太小则统计量不稳定)
- 训练和推理(inference /ˈɪnfərəns/)行为不一致(训练用 batch 统计量,推理用全局移动平均)
- 对 RNN / Transformer 不友好(序列长度变化)
4.2 Layer Normalization(层归一化)
与 Batch Norm 不同,Layer Norm 对每个样本的所有特征维度做归一化:
不受 batch size 影响,在 Transformer / RNN 中是标配。
| Batch Norm | Layer Norm | |
|---|---|---|
| 归一化维度 | batch × 特征 | 特征 |
| 适用架构 | CNN(CV) | RNN / Transformer(NLP) |
| Batch 依赖 | 强(小 batch 效果差) | 无 |
| 训练/推理一致性 | 不一致 | 一致 |
4.3 RMS Norm(均方根归一化)
Layer Norm 的简化版本,去掉了均值中心化(只除方差,不减均值):
直觉:Layer Norm 中减均值操作对 Transformer 效果贡献不大(注意力的输出本身是零均值的?),去掉后计算量减少,实验效果仍接近甚至更好。LLaMA、T5 等模型都使用 RMS Norm。
| Norm | 减均值? | 除方差? | 可学习参数 | 计算量 |
|---|---|---|---|---|
| Batch Norm | ✓ | ✓ | 中(跨样本统计) | |
| Layer Norm | ✓ | ✓ | 高(逐样本统计所有特征) | |
| RMS Norm | ✗ | ✓(仅 RMS) | 低 |
5. 正则化(Regularization)
5.1 Dropout
训练时以概率
推理时保留所有神经元,且权重乘以
直觉:防止神经元之间产生共适应(co-adaptation)。如果某个神经元过度依赖另一个神经元才会做出正确判断,Dropout(/ˈdrɒpaʊt/) 会强迫它学会独立解决问题。
5.2 权重衰减(Weight Decay)
在损失函数中加入权重的
梯度更新变为:
即每次更新前先将权重"缩小"一个比例
直觉:
- 防止某些权重变得过大(过度关注某个特征)
- 等价于在贝叶斯框架下对权重施加高斯先验
- AdamW 的关键改进就是让 weight decay 不被自适应学习率扭曲
5.3 标签平滑(Label Smoothing)
将硬标签(hard label)替换为软标签(soft label):
其中
例如:
直觉:硬标签强迫模型输出 logit 无限大(往
- 提高泛化能力
- 防止 logit 过大
- 提高对抗鲁棒性
5.4 正则化方法对比
| 方法 | 适用阶段 | 原理 | 关键超参数(hyperparameter /ˈhaɪpərpəˈræmɪtər/) |
|---|---|---|---|
| Dropout | 训练前向 | 随机丢弃 → 集成学习 | |
| Weight Decay | 训练反向 | ||
| Label Smoothing | 损失函数 | 软标签 → 降低过自信 |
6. 代码实验:实际对比
下面的代码在 MNIST 上用 2 层 MLP 对比不同初始化、优化器和学习率调度的收敛效果。
6.1 运行代码
bash
cd ai/04-neural-networks/code
python training_techniques.py6.2 实际输出
Device: cpu
============================================================
Training Techniques Comparison on MNIST
============================================================
Device: cpu | Epochs: 10 | Subset: 2000 | LR: 0.001
Train batches: 32 | Test batches: 157
============================================================
Experiment 1: Weight Initialization Comparison
============================================================
Init | Epoch | Train Loss | Train Acc | Test Acc
------------------------------------------------------------
[Init] Using xavier initialization
xavier | 10 | 0.0374 | 0.9985 | 0.9219
[Init] Using kaiming initialization
kaiming | 10 | 0.0353 | 0.9990 | 0.9198
[Init] Using llama initialization
llama | 10 | 0.1011 | 0.9850 | 0.9142
Final Test Accuracy by Initialization:
Init | Test Acc
-------------------------
xavier | 0.9219
kaiming | 0.9198
llama | 0.9142
============================================================
Experiment 2: Optimizer Comparison
============================================================
Optimizer | Epoch | Train Loss | Train Acc | Test Acc
------------------------------------------------------------
[Init] Using kaiming initialization
SGD | 10 | 1.3994 | 0.5705 | 0.5658
[Init] Using kaiming initialization
Momentum | 10 | 0.3738 | 0.9015 | 0.8707
[Init] Using kaiming initialization
Adam | 10 | 0.0355 | 0.9990 | 0.9198
[Init] Using kaiming initialization
AdamW | 10 | 0.0354 | 0.9985 | 0.9209
Final Test Accuracy by Optimizer:
Optimizer | Test Acc
-------------------------
SGD | 0.5658
Momentum | 0.8707
Adam | 0.9198
AdamW | 0.9209
============================================================
Experiment 3: Learning Rate Schedule Comparison
============================================================
Scheduler | Epoch | Train Loss | Train Acc | Test Acc
------------------------------------------------------------
[Init] Using kaiming initialization
none | 10 | 0.0167 | 1.0000 | 0.9231
cosine | 10 | 0.0402 | 0.9980 | 0.9217
step | 10 | 0.0476 | 0.9985 | 0.9220
warmup_cosine | 10 | 0.0350 | 0.9990 | 0.9202
Final Test Accuracy by LR Schedule:
Scheduler | Test Acc
----------------------------
none | 0.9231
cosine | 0.9217
step | 0.9220
warmup_cosine | 0.92026.3 实验结果分析
初始化对比:
- 三种初始化在 MNIST 上表现接近(~91-92%),因为 2 层 MLP 的网络深度较浅,初始化差异不明显
- Xavier 和 Kaiming 略优于 LLaMA 的简单正态缩放——LLaMA init 是专门为深层 Transformer 设计的
- Kaiming 的 Train Loss 最低,说明它确实最适合 ReLU 网络
优化器对比:
- SGD:仅收敛到 56.6%(学习率 1e-3 对 SGD 偏小)
- Momentum:提升至 87.1%(动量显著加速)
- Adam / AdamW:均达到 ~92%, AdamW 略高 0.1%(由于 weight decay 的正则化效果)
这里明显看到 Momentum 比 SGD 提升了 30 个百分点,而 Adam 又在 Momentum 上提升了 5 个百分点——这就是优化器进化的力量。
学习率调度对比:
- Constant(无调度)反而最高(92.3%),因为 MNIST 简单的 10 epoch 训练不足以让调度策略充分体现优势
- Step 和 Cosine 略低,但理论上在更长训练周期中会表现更好
- Warmup+Cosine 在训练后期能稳定优化,对于更深层的网络(如 ResNet-50、Transformer)至关重要
6.4 Loss 曲线
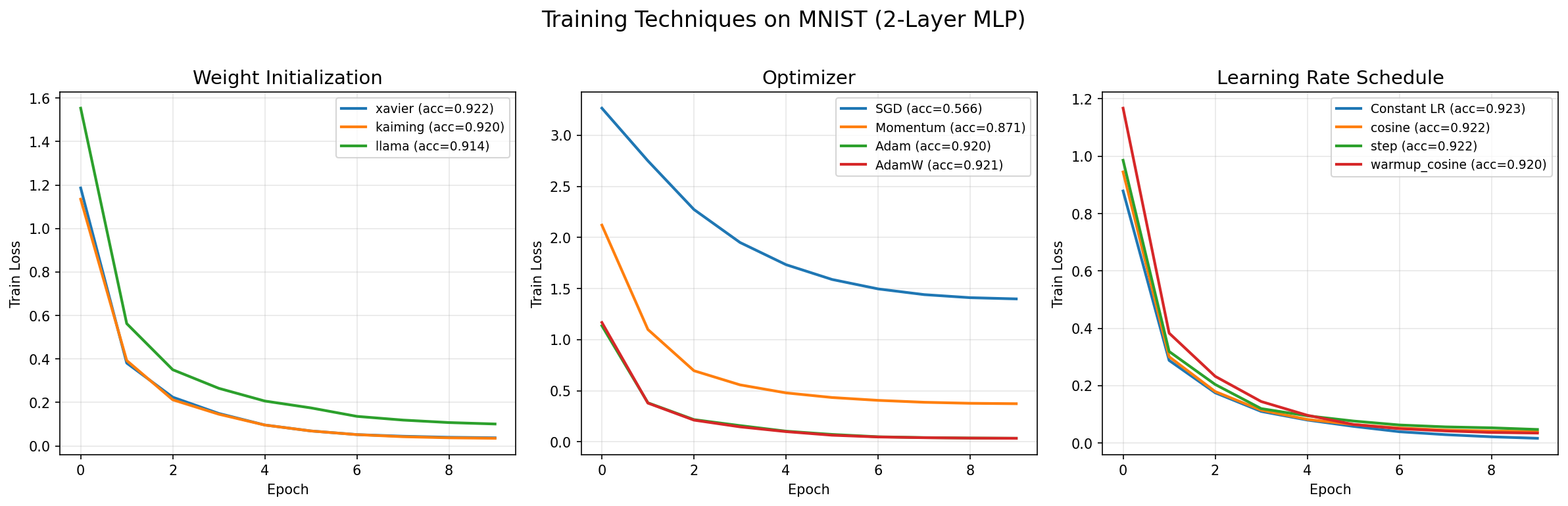
总结
训练技巧流水线
│
├─ 1. 权重初始化 ───── 决定起点
│ ├─ Xavier: tanh/sigmoid → Var(W) = 2/(n_in + n_out)
│ ├─ Kaiming: ReLU → Var(W) = 2/n_in
│ └─ LLaMA: Transformer → 0.02 / √(2n_layer)
│
├─ 2. 优化器 ────────── 决定路径
│ ├─ SGD → w -= η∇L
│ ├─ Momentum → v = βv + ∇L, w -= ηv
│ ├─ Adam → m, v 自适应 + 偏差修正
│ └─ AdamW* → 解耦 weight decay(当前主流)
│
├─ 3. 学习率调度 ──── 决定步长
│ └─ Warmup + Cosine* → 初期稳定 → 平滑衰减(LLM 标配)
│
├─ 4. 归一化层 ────── 稳定中间特征
│ ├─ Batch Norm → 跨样本归一化(CV 标配)
│ ├─ Layer Norm → 逐样本归一化(NLP 标配)
│ └─ RMS Norm* → LN 简化版(LLaMA/T5)
│
└─ 5. 正则化 ──────── 防止过拟合
├─ Dropout → 随机丢弃(集成效果)
├─ Weight Decay → L2 惩罚(贝叶斯先验)
└─ Label Smoothing → 软标签(降低过自信)核心建议:
- 新项目直接从 Kaiming init + AdamW + Warmup+Cosine 起步
- CV 模型使用 Batch Norm,NLP/序列模型使用 Layer Norm / RMS Norm
- 数据量小时用 Dropout + Weight Decay;数据量大时 Weight Decay 优先
下一章,我们将深入Transformer 架构,理解注意力机制如何成为现代深度学习的基石。
参考文献 (References)
- Glorot, X. & Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. AISTATS.
- Srivastava, N. et al. (2014). Dropout: A simple way to prevent neural networks from overfitting. JMLR, 15, 1929–1958.
- Ioffe, S. & Szegedy, C. (2015). Batch normalization: Accelerating deep network training. ICML.
- Kingma, D. P. & Ba, J. (2015). Adam: A method for stochastic optimization. ICLR.
- Loshchilov, I. & Hutter, F. (2019). Decoupled weight decay regularization. ICLR.