Appearance
第2章 反向传播 — 神经网络的学习算法
Chapter 2: Backpropagation — The Learning Algorithm of Neural Networks
反向传播(backpropagation /ˌbækprəpəˈɡeɪʃən/) (Backpropagation) 是深度学习最核(kernel /ˈkɜːrnl/)心的训练算法。 它将微积分中的链式法则应用于多层神经网络,优雅地解决了"如何计算每个参数(parameter /pəˈræmɪtər/)对最终误差的贡献"这一根本问题。本章从一个简单的计算图出发,逐步推导出 2 层神经网络的反向传播公式,并通过 NumPy 实现和数值梯度(gradient /ˈɡreɪdiənt/)验证来确保推导的正确性。
时间线:
- 1986: Rumelhart, Hinton & Williams 在 Nature 发表反向传播算法
Backpropagation is the core training algorithm of deep learning. It applies the chain rule from calculus to multi-layer neural networks, elegantly solving the fundamental problem of "how to compute each parameter's contribution to the final error." This chapter starts from a simple computation graph, derives backpropagation for a 2-layer network step by step, and verifies correctness through NumPy implementation and numerical gradient checking.
前置知识 (Prerequisites): 微积分(链式法则),线性代数(矩阵乘法),第 1 章(感知机与 MLP)
依赖库 (Dependencies): numpy, matplotlib
Code companion: code/backpropagation.py
目录 (Table of Contents)
- 计算图 (Computation Graph) 📐
- 1.1 前向传播的图形化表示
- 1.2 计算图上的梯度传播
- 链式法则递归应用 📐
- 2.1 输出层 (Layer 2)
- 2.2 隐藏层 (Layer 1)
- 2.3 梯度汇总
- 数值梯度验证 (Gradient Check)
- 2 层网络的完整实现
- 关键总结 (Key Summary)
1. 计算图 (Computation Graph)
1.1 前向传播的图形化表示 (Forward Pass Visualization)
计算图是理解反向传播最直观的工具。考虑一个最简单的网络:一个神经元 + 一个 Sigmoid(/ˈsɪɡmɔɪd/) + 平方误差。
对于单个样本
这个前向过程可以用计算图直观表示:
x ──┐
├──→ (+) ── z ──→ [σ] ── a ──→ [½(·-y)²] ── L
w ──┤ ↑
b ──┘ 偏置从左到右: 输入
和权重 做线性组合,加上偏置 得 ,Sigmoid 激活得 ,最后与目标 比较得损失 。
关键洞察: 要更新
这正是反向传播的本质——从输出端往输入端逐层传递梯度。
1.2 计算图上的梯度传播 (Gradient Flow on Computation Graph)
让我们实际计算每个局部梯度:
| 节点 | 局部梯度 | 表达式 |
|---|---|---|
因此:
这虽然只是一个神经元的梯度,但它揭示了反向传播的核心模式:
梯度 = 上游梯度 × 局部梯度 (Gradient = upstream gradient × local gradient)
当我们堆叠多层时,这个模式会递归应用,形成误差反向传播(errors backpropagating from output to input)。
🔍 完整演算:单神经元梯度计算 — w=2,x=3,y=0
📐 公式
对于单个神经元,前向计算:
反向传播的链式法则:
其中
📖 参数含义
| 符号 | 名称 | 含义 |
|---|---|---|
| 权重 | 神经元的连接权重,控制输入信号的缩放 | |
| 偏置 | 神经元的偏置项,控制激活阈值 | |
| 输入 | 单个样本的特征值 | |
| 目标值 | 样本的真实标签 | |
| 线性输出 | ||
| 激活输出 | ||
| 损失 | 均方误差 | |
| 误差信号 | ||
| 权重梯度 | 损失对权重的导数,用于梯度下降更新 |
📝 公式来源
链式法则的逐层拆解:
各局部梯度:
合并得到完整梯度公式:
✏️ 手算演示
给定参数:
Step 1: 前向传播
Step 2: 反向传播 — 逐层求导
Step 3: 链式法则合成
验证:上游梯度 × 局部梯度
梯度流动路径:
最终梯度
🌍 实际意义
- 上游梯度 × 局部梯度 = 反向传播的核心模式:这个简单例子揭示了整个深度学习的梯度计算本质。每一层只负责计算自己的局部梯度,上游传来的梯度与局部梯度相乘后继续向前传播。
- Sigmoid 的梯度消失现象:当
很大( )时, 非常小。深层网络中多个小梯度连乘会导致梯度消失(Vanishing Gradient)——这就是为什么现代网络更倾向使用 ReLU 的原因。 (误差信号)的概念: 衡量了该神经元对最终误差的"责任",是反向传播中最核心的中间量。
2. 链式法则递归应用 (Recursive Chain Rule)
现在考虑一个 2 层神经网络(1 个隐藏层 + 1 个输出层),使用 Tanh 隐藏激活和 Sigmoid 输出激活。
符号定义 (Notation)
| 符号 | 含义 | 维度 |
|---|---|---|
| 输入矩阵 | ||
| 第一层权重、偏置 | ||
| 第一层线性输出、隐藏激活 | ||
| 第二层权重、偏置 | ||
| 第二层线性输出、预测 | ||
| 真实标签 | ||
| 二元交叉熵(entropy /ˈentrəpi/)损失 | 标量(scalar /ˈskeɪlər/) |
前向传播 (Forward Pass)
2.1 输出层 (Layer 2 — Output Layer)
梯度 1:
对于二元交叉熵 + Sigmoid,有一个非常简洁的合并梯度形式:
设
,我们称 为输出层的误差信号 (error signal)。
梯度 2:
应用链式法则:
注意
,这是因为 ,维度为 。
矩阵形式的最终公式:
2.2 隐藏层 (Layer 1 — Hidden Layer)
误差传播到第一层
现在我们要把
通过激活函数传播
接着通过 Tanh 激活函数:
其中
表示逐元素乘法 (Hadamard product)。
对
矩阵形式的最终公式:
2.3 梯度汇总 (Gradient Summary)
Layer 2 (Output) Layer 1 (Hidden)
┌──────────────────────┐ ┌──────────────────────┐
│ δ₂ = ŷ - y │ │ δ₁ = (δ₂W₂ᵀ) ⊙ t'(z₁)│
│ dW₂ = (h₁ᵀ δ₂) / N │ ←───│ dW₁ = (Xᵀ δ₁) / N │
│ db₂ = mean(δ₂) │ │ db₁ = mean(δ₁) │
└──────────────────────┘ └──────────────────────┘
│ │
│ δ₂ "flows back" │
└────────────────────────────────┘核心模式 (The Core Pattern):
每一层的反向传播遵循统一的 三部曲:
其中
🔍 完整演算:2 层网络反向传播手算 — 2→2→1
📐 公式
2 层神经网络(Tanh 隐藏层 + Sigmoid 输出层 + 二元交叉熵损失):
输出层梯度:
隐藏层梯度:
📖 参数含义
| 符号 | 名称 | 含义 |
|---|---|---|
| 输入、真实标签 | 单个样本: | |
| 隐藏层权重、偏置 | ||
| 输出层权重、偏置 | ||
| 输出层误差信号 | ||
| 隐藏层误差信号 | ||
| Hadamard 积 | 逐元素乘法 |
📝 公式来源
反向传播 = 递归链式法则:
输出层:
✏️ 手算演示
网络结构与参数:
单个样本:
Step 1: 前向传播
Step 2: 输出层反向传播
Step 3: 误差传播到隐藏层
Step 4: 隐藏层梯度
Step 5: 梯度流动表
| 传播方向 | 变量 | 数值/表达式 | 维度 | 含义 |
|---|---|---|---|---|
| 前向 | 隐藏层线性输出 | |||
| ↓ | Tanh 激活 | |||
| ↓ | 输出层线性输出 | |||
| ↓ | Sigmoid 预测 | |||
| 反向 ↑ | 输出误差信号 | |||
| ↑ | 输出层权重梯度 | |||
| ↑ | 对隐藏层的梯度 | |||
| ↑ | 隐藏层误差信号 | |||
| ↑ | 隐藏层权重梯度 |
🌍 实际意义
- 误差信号
的物理含义: 表示预测 低于真实值 ,因此梯度会推动权重增加预测值。 中第一个神经元为负( )、第二个为正( ),反映了它们对输出误差的不同"责任"。 - 梯度流动的可视化:从
往 方向,误差信号 经历"输出层 → 权重回传 → 激活函数门控"的标准三步曲,每一步都乘以一个局部梯度。 - 现实训练中的应用:实际训练时(如第 4 节的代码实现),上述手算过程以矩阵形式对批量数据一次性完成。梯度检查(第 3 节)本质上就是用数值近似验证上述每一组梯度的正确性。
3. 数值梯度验证 (Gradient Check)
反向传播的推导容易出错。数值梯度验证 (Gradient Check) 是确保推导正确的黄金标准。
有限差分法 (Finite Differences)
使用中心差分 (central difference) 近似导数:
为什么不用前向差分
? 中心差分的误差为 ,而前向差分的误差为 。在 下,中心差分的精度远高于前向差分。
验证标准 (Verification Criteria)
如果反向传播实现正确,对于每个参数
代码实现 (Code Implementation)
python
def gradient_check(model, X, y, param_name="W2", num_tests=5):
"""
数值梯度验证: |analytical - numerical| < 1e-6
使用中心差分: ∂f/∂θ ≈ (f(θ+ε) - f(θ-ε)) / (2ε)
"""
param = model.params[param_name]
analytical_grad = model.grads[param_name].copy()
flat_analytical = analytical_grad.ravel()
total_dims = flat_analytical.size
# 如果参数小, 测试所有维度; 否则随机采样
if total_dims <= 20:
test_indices = list(range(total_dims))
else:
test_indices = RNG.choice(
total_dims, min(num_tests, total_dims), replace=False
).tolist()
max_diff = 0.0
for idx in test_indices:
orig_val = param.ravel()[idx]
# f(θ + ε)
param_plus = param.copy()
param_plus.ravel()[idx] += EPS
loss_plus = model.compute_loss_with_params(
{param_name: param_plus}, X, y
)
# f(θ - ε)
param_minus = param.copy()
param_minus.ravel()[idx] -= EPS
loss_minus = model.compute_loss_with_params(
{param_name: param_minus}, X, y
)
num_grad = (loss_plus - loss_minus) / (2 * EPS)
ana_grad = flat_analytical[idx]
diff = abs(ana_grad - num_grad)
max_diff = max(max_diff, diff)
return max_diff运行输出 (Actual Output)
========================================================================
【数值梯度验证 / Numerical Gradient Check】
有限差分步长 (Finite diff step): ε = 1e-05
每个参数测试 (Tests per param): 5 个随机位置
========================================================================
参数 W1 ✓ PASS | shape=(2, 10) | max|diff|=1.30e-11 | rel_err=1.24e-10
[0,0] analytical=-1.04903863e-01 numerical=-1.04903863e-01 |diff|=3.55e-12
[0,1] analytical=+2.28319969e-02 numerical=+2.28319969e-02 |diff|=8.81e-12
...
[1,9] analytical=-1.18234050e-02 numerical=-1.18234050e-02 |diff|=2.18e-12
参数 b1 ✓ PASS | shape=(1, 10) | max|diff|=7.66e-12 | rel_err=3.41e-10
参数 W2 ✓ PASS | shape=(10, 1) | max|diff|=1.43e-11 | rel_err=3.69e-11
参数 b2 ✓ PASS | shape=(1, 1) | max|diff|=1.62e-12 | rel_err=7.74e-11
✓ 所有梯度检查通过! |analytical - numerical| < 1e-6所有 4 组参数的梯度检查全部通过,最大绝对差值
,远小于 的阈值。这以数值方式证明了我们推导的反向传播公式是正确的。
4. 2 层网络的完整实现 (Complete 2-Layer Implementation)
4.1 前向与反向传播 (Forward & Backward)
python
class TwoLayerNet:
"""2 层神经网络: 输入 → 隐藏层(tanh) → 输出层(sigmoid)"""
def __init__(self, input_dim=2, hidden_dim=10):
scale1 = np.sqrt(1.0 / input_dim)
scale2 = np.sqrt(1.0 / hidden_dim)
self.params = {
"W1": np.random.randn(input_dim, hidden_dim) * scale1,
"b1": np.zeros((1, hidden_dim)),
"W2": np.random.randn(hidden_dim, 1) * scale2,
"b2": np.zeros((1, 1)),
}
self.cache = {}
def forward(self, X):
"""前向传播: X → z1 → h1 → z2 → y_hat"""
z1 = X @ self.params["W1"] + self.params["b1"]
h1 = np.tanh(z1)
z2 = h1 @ self.params["W2"] + self.params["b2"]
y_hat = 1.0 / (1.0 + np.exp(-np.clip(z2, -500, 500)))
self.cache = {"X": X, "z1": z1, "h1": h1, "z2": z2, "y_hat": y_hat}
return y_hat
def backward(self, y):
"""反向传播 — 计算所有参数的梯度"""
X = self.cache["X"]
h1 = self.cache["h1"]
y_hat = self.cache["y_hat"]
N = X.shape[0]
# 输出层: δ₂ = ŷ - y
delta2 = y_hat - y
dW2 = (h1.T @ delta2) / N
db2 = np.mean(delta2, axis=0, keepdims=True)
# 隐藏层: δ₁ = (δ₂W₂ᵀ) ⊙ (1 - h₁²)
delta1 = (delta2 @ self.params["W2"].T) * (1.0 - h1 ** 2)
dW1 = (X.T @ delta1) / N
db1 = np.mean(delta1, axis=0, keepdims=True)
self.grads = {"W1": dW1, "b1": db1, "W2": dW2, "b2": db2}
return self.grads4.2 梯度检查结果 (Gradient Check Results)
我们用 backpropagation.py 中的 full_gradient_check() 对所有 4 组参数验证。结果:
✓ W1: max|diff| = 1.30e-11 (through 20 dimensions)
✓ b1: max|diff| = 7.66e-12 (through 10 dimensions)
✓ W2: max|diff| = 1.43e-11 (through 10 dimensions)
✓ b2: max|diff| = 1.62e-12 (through 1 dimension)所有 |diff| 在
到 量级,远低于 阈值。反向传播公式正确!
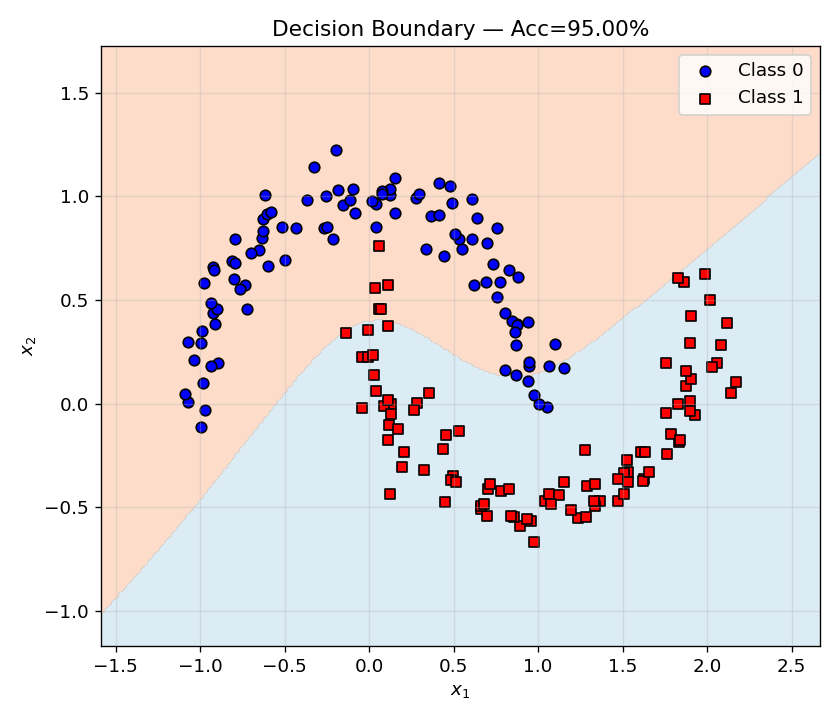
4.3 训练与决策边界 (Training & Decision Boundary)
在 sklearn 风格的 moons 二分类(classification /ˌklæsɪfɪˈkeɪʃən/)数据集上训练(200 样本,noise=0.1):
Step 5: Training
Epoch 1 | Loss = 0.927862 | Acc = 0.3600
Epoch 100 | Loss = 0.290621 | Acc = 0.8600
Epoch 200 | Loss = 0.285902 | Acc = 0.8600
Epoch 300 | Loss = 0.278738 | Acc = 0.8750
Epoch 400 | Loss = 0.237570 | Acc = 0.8850
Epoch 500 | Loss = 0.151477 | Acc = 0.9500
Final loss: 0.151477
Final acc: 0.9500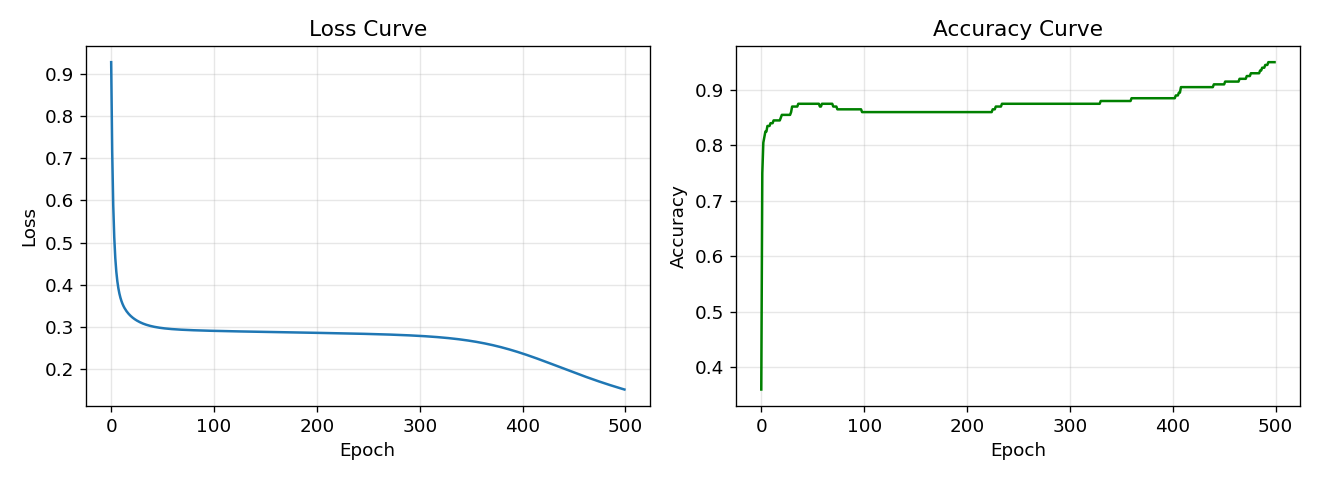
损失从 0.928 降至 0.151,准确率从 36% 提升至 95%。500 个 epoch 后的决策边界清晰地分离了两个半月形:
本章演算盒索引
| 位置 | 演算盒 | 跳转 |
|---|---|---|
| §1 | 🔍 单神经元梯度计算 — w=2,x=3,y=0 | 跳转 |
| §2 | 🔍 2 层网络反向传播手算 — 2→2→1 | 跳转 |
5. 关键总结 (Key Summary)
核心公式
| 概念 | 公式 | 含义 |
|---|---|---|
| 误差信号 | 上层误差通过权重回传,经激活函数导数的"门控" | |
| 权重梯度 | 下层激活 × 本层误差信号 | |
| 偏置梯度 | 误差信号的平均值 | |
| 数值梯度验证 | 中心差分, |
关键洞察
- 链式法则是唯一需要的数学工具 — 反向传播就是递归地应用链式法则,从输出层逐层向输入层传播梯度
- 局部梯度 × 传播梯度 = 参数梯度 — 每个节点的梯度 = 上游传播来的梯度 × 该节点自身的局部梯度
- 梯度检查是调试的必备技能 — 在实现新的网络结构时,永远先用数值梯度验证你的解析梯度
- "误差反向传播"这个名字很贴切 —
就是"误差信号",它从输出层开始,逐层向后"传播"
与后续章节的联系
| 后续章节 | 联系 |
|---|---|
| 第 3 章 (训练技巧) | 反向传播的改进:动量(momentum /məˈmentəm/)、Adam、梯度裁剪 |
| 第 4 章 (CNN) | 反向传播在卷积(convolution /ˌkɒnvəˈluːʃən/)层中的适配(卷积转置) |
| 第 5 章 (RNN) | 通过时间的反向传播 (BPTT) |
| Transformer(/trænsˈfɔːrmər/) | 自注意力(attention /əˈtenʃən/)的反向传播 — 更复杂的计算图 |
动手练习
- 推导练习: 为 3 层网络(2 个隐藏层 + 1 个输出层)推导反向传播公式
- 代码练习: 将隐藏层激活从 Tanh 改为 ReLU,修改
backward()中的对应行,验证梯度检查仍通过 - 实验练习: 在
backpropagation.py中改变隐藏层神经元数(5, 10, 20, 50),观察最终准确率的变化 - 深入练习: 添加 L2 正则化(regularization /ˌreɡjələraɪˈzeɪʃən/),推导修改后的梯度公式,验证梯度检查
下章预告: 第 3 章将介绍训练技巧 (Training Techniques) — 权重初始化、批归一化(normalization /ˌnɔːrmələˈzeɪʃən/) (Batch Normalization)、Dropout(/ˈdrɒpaʊt/)、学习率调度等让神经网络训练更稳定的实用技术。
Last updated: 2026-06-02
参考文献 (References)
- Rumelhart, D. E., Hinton, G. E. & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533–536.
- LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE, 86(11), 2278–2324.